Analysis
In the 2019 "Beat the Judge" writing contest, organized by @knotanumber, writers were invited to submit stories and then rank those of their competitors, but not their own. The story with the best aggregate score was awarded the title of "Writer's Choice". The story submissions included many different genres from people representing a cross-section of WattPad writers. The data from this contest provided an opportunity to observe the variability of reader preferences.
The variances in the story rankings were much greater than expected. Ranking differences among the group likely reflected personal preferences in genre, style, structure, complexity, inclusion of mature themes, and perhaps other factors.
The dataset was too small to make any far-reaching quantitative conclusions, but was indicative of the wide range of personal preferences among readers. The implications are:
1. The results of the various Wattpad writing contests likely depend much on the judges personal preferences and likes. A story submitted in one contest with a particular judge may rank well while the same story in another contest with another judge may rank poorly. Genre restrictions and clear judging criteria would be expected to minimize the influences of personal preference, but likely not eliminate them.
2. Widely varying reader preferences would actually support a wide range of genres and writing styles on Wattpad, and thus a large number and diversity of writers.
Basis
· Sixteen writers submitted stories to "Beat the Judge" contest. Several genres were represented, including fantasy, science fiction, historical fiction, romance, paranormal, poetry, and others. Each writer had their own unique style and voice.
· Each writer was tasked with reading a given amount of every story in the contest and rank the top ten in order, but excluding their own story. Thirteen of the sixteen writers submitted rankings.
· No specific judging criteria was provided, rather each writer used their own.
· For privacy, the data was blinded before being provided for analysis. The stories were designated as 'Book #1' through 'Book #16' in no particular order. Submitted rankings of ten (highest rating) through one (lowest rating) for each story were provided in the dataset. These were also cross-referenced by submitter (also blinded) to check for consistency. Those rankings that did not make the top ten were designated as zero for the purpose of analysis.
Results
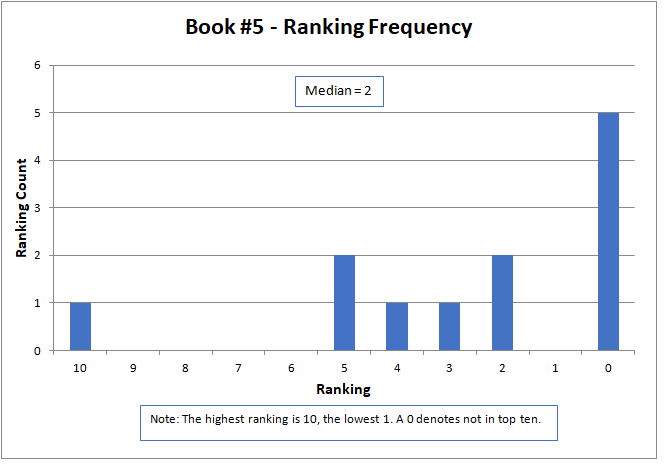
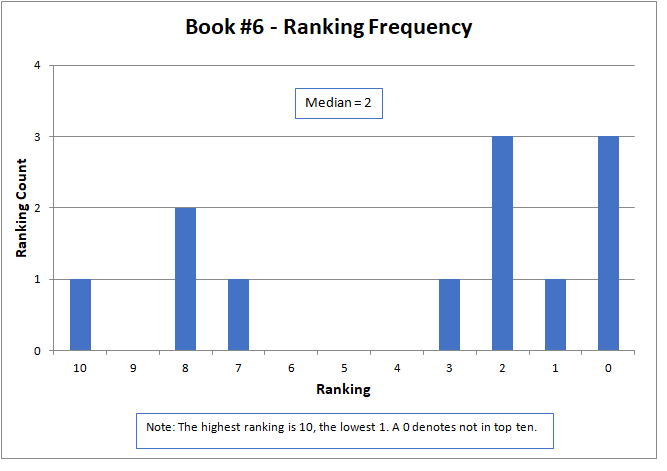
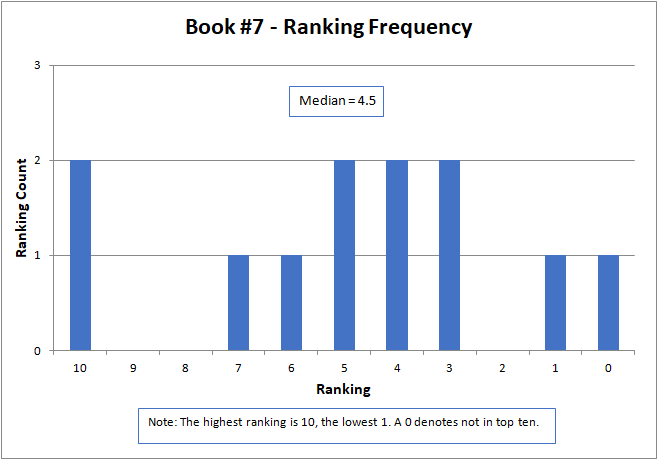
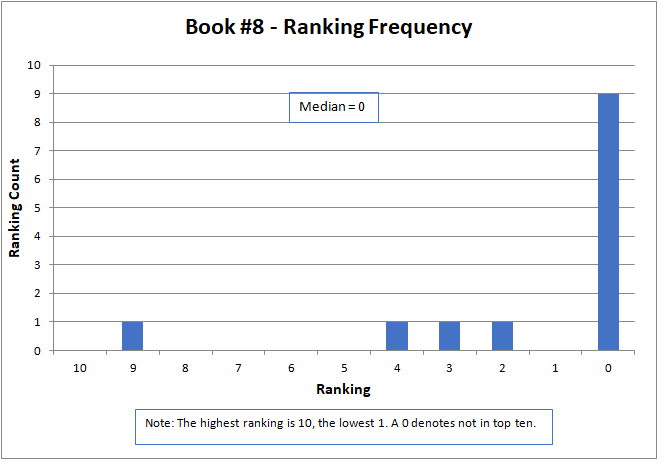
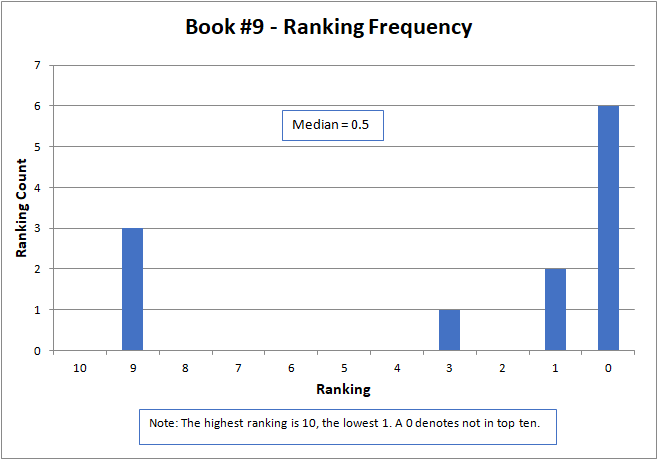
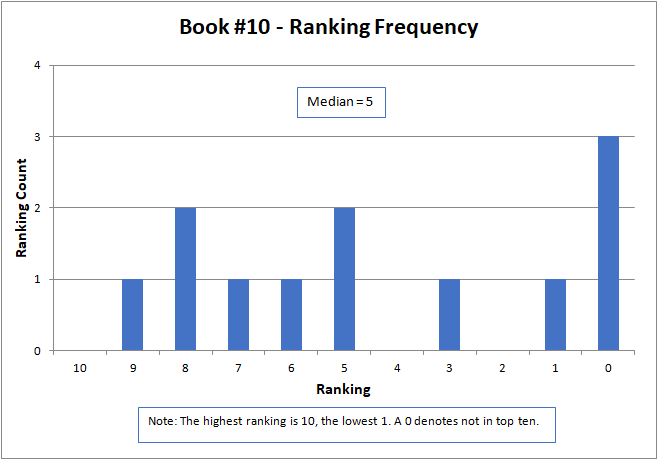
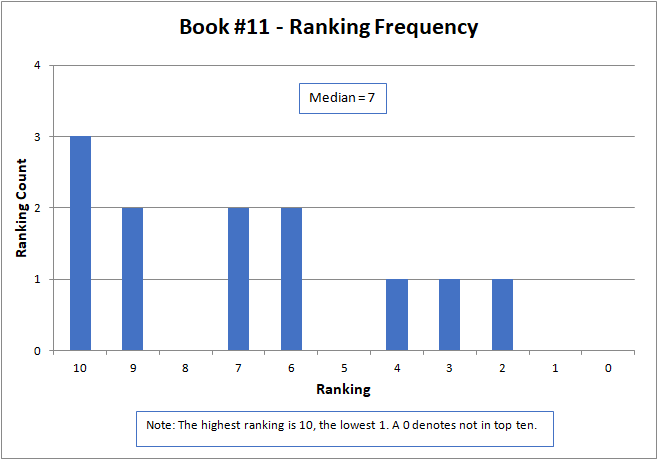
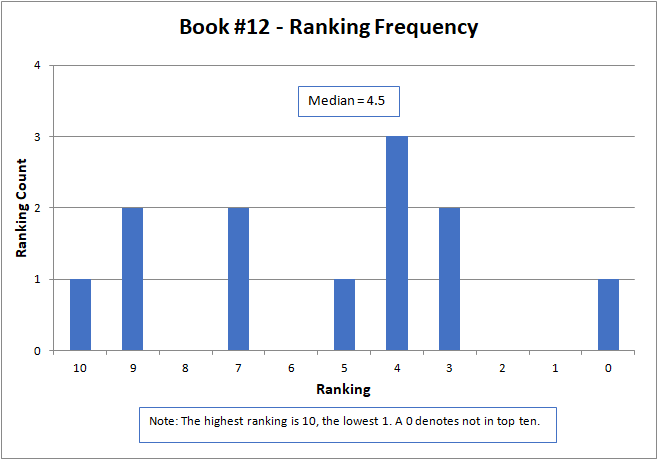
The results are shown graphically below for each story. The nature of the data did not lend itself to analysis by common statistical parameters, such as mean and standard deviation. To be meaningful, these generally required continuous numerical data and presume a normal data distribution. However, median is an appropriate parameter for comparison. Here, the median is defined as the midpoint of the distribution of rankings, where half the rankings are lower and half higher.
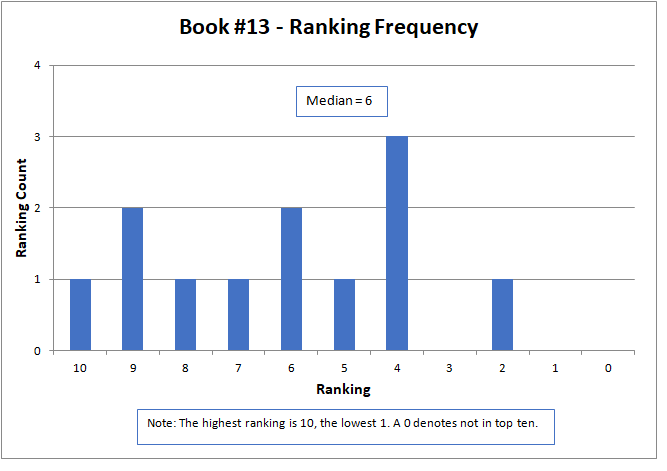
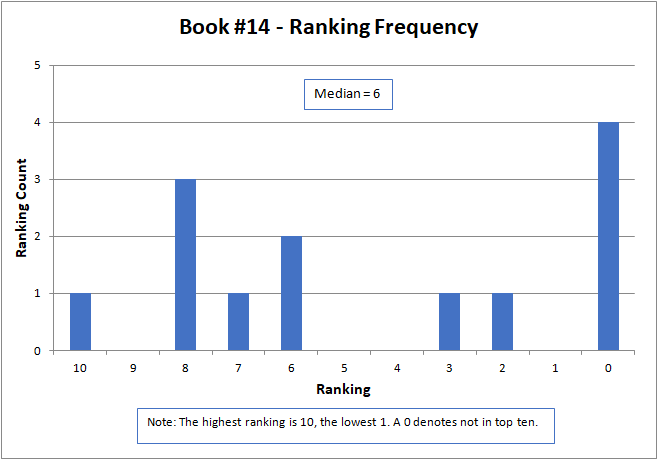
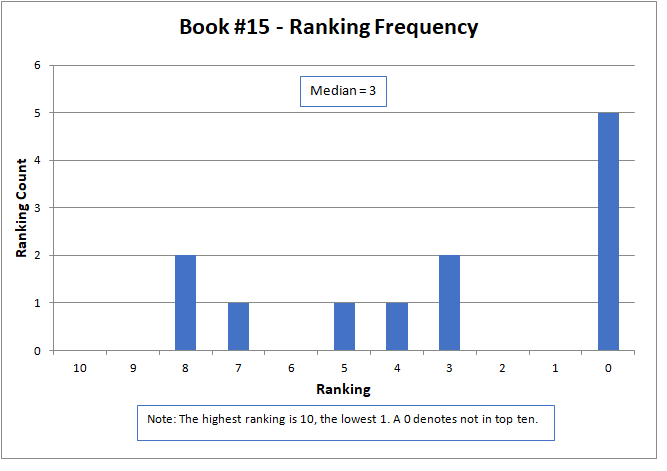
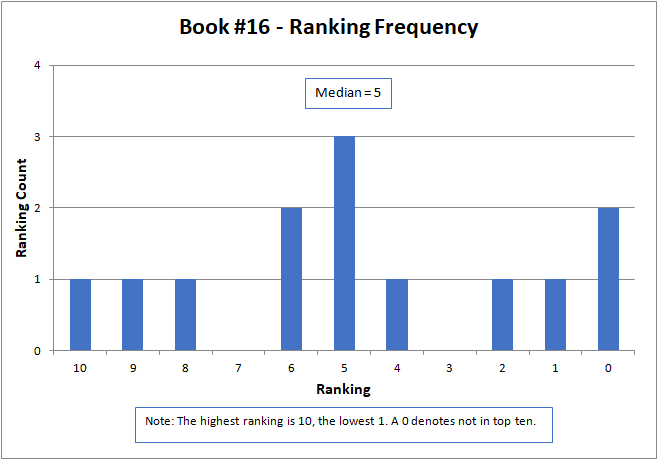
The median approximated the final contest results, with a higher number being better, but did not match them exactly. The actual results were determined by a sum of ratings, but only for those thirteen contestants that submitted rankings as required by the contest rules. The charts below present all sixteen of the original submitted stories.
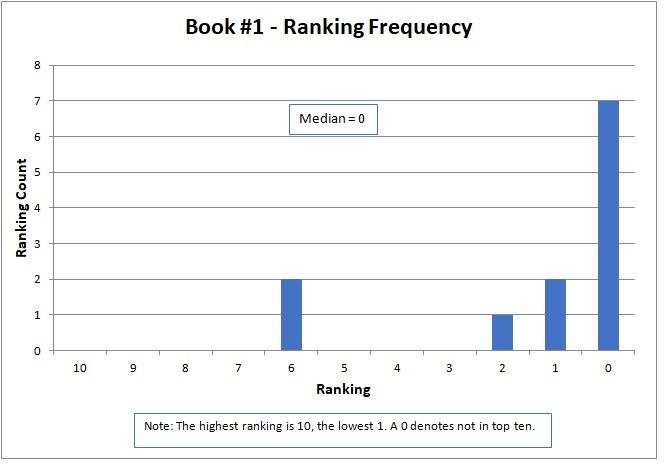
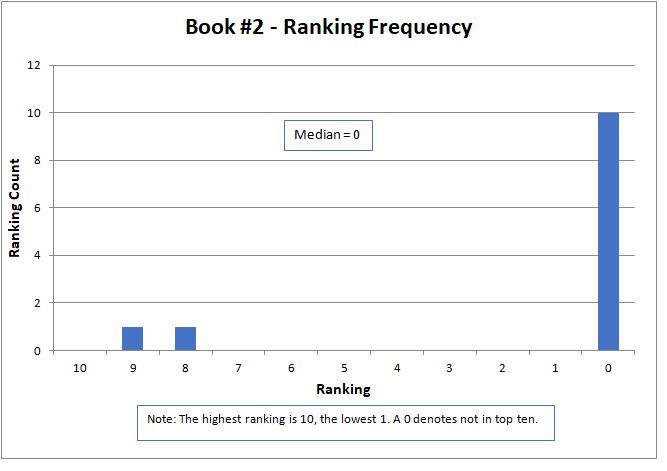
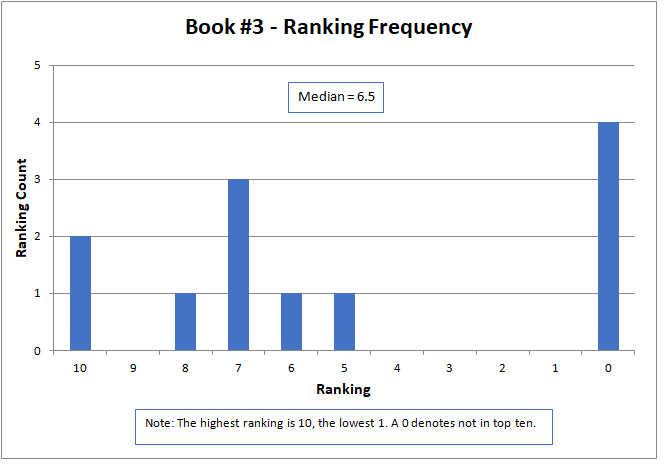
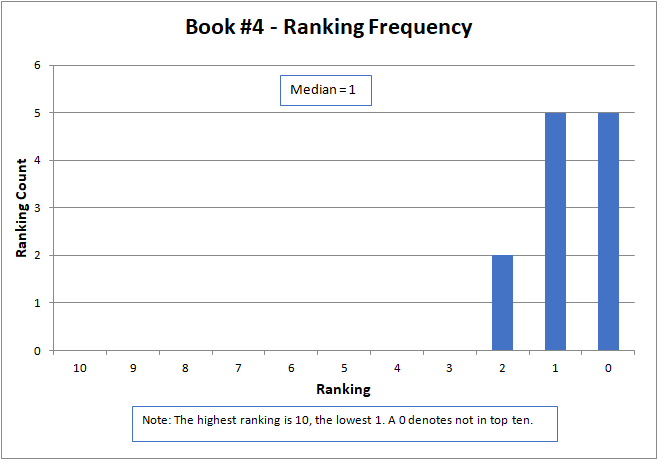
The variation of rankings can best be seen visually in the charts. For instance with Story #1, two people gave it a ranking of six, one person as two, two people as one, and seven people ranked it as not in the top ten (zero). Recall that a ranking of ten is the best possible score. Books #3, #6, and #14 had the widest variation, with rankings spread across the charts and at both ends of the scale. Only two stories, Books #11 and #13, did not have at least one ranking of zero (that is, not in the top ten).
Bạn đang đọc truyện trên: AzTruyen.Top